

Vibes-based evals and Weights & Biases' second act
Plus, a Llama 3 price war is brewing, and what Snowflake's new model means for pre-training.


Author’s note: covering a few things today starting with some notes on Llama 3 for free subscribers, and then a deeper dive into Weights & Biases and its next act and Snowflake’s latest move into LLMs.
OpenAI’s price advantage is eroding even further
Last week, Meta did the Meta thing where it released a family of new Llama models, which are smaller open-ish source models that are trained on a ton amount of data for a really long time. (The largest of the family isn’t done training.)
OpenAI already had to contend with a series of products that were highly competitive with GPT-3.5 Turbo, it’s workhorse model designed for most tasks. Its advantage was it was comically easy to implement, even as other providers started to release drop-in replacements endpoints over the past year that only require a few lines of code.
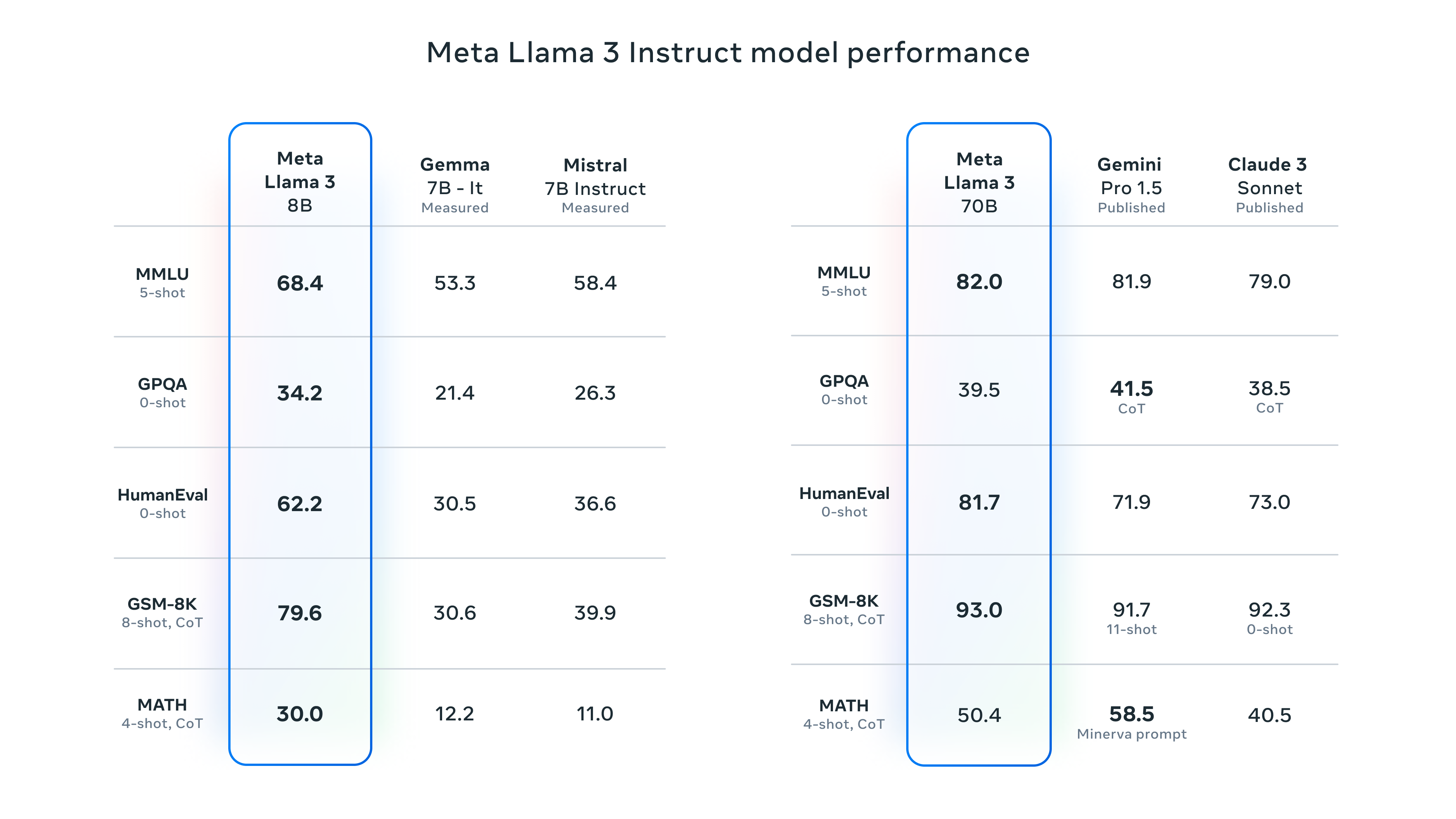
As expected, The Llama 3 models that came out are good. There are more than enough technical teardowns out there and I’ll leave it up to the experts for that analysis. But its middle-of-the-road version, Llama 3 70B, is reaching the point where giving up that kind of consolidated enterprise experience—where you get a bunch of tools beyond just text completion in a single product—is actually starting to make sense because it’s really cheap.
That combination of pretty cheap and all-in-one has long been OpenAI’s advantage. You are only paying one company for a lot of stuff. But Llama 3 70B pretty much smushes GPT-3.5 Turbo when it comes to most benchmarks (yes, we’re doing this again), while still being cheaper than its workhorse GPT-3.5 Turbo.
{kind=link}
OpenAI was already staring down a lot of new “rivals” that were basically riding the open source wave to offer really competitive products to GPT-3.5 Turbo thanks to releases from Mistral. Together AI, Fireworks, and others all rolled out endpoints for Mixtral which offered GPT-3.5 Turbo level scores for a fraction of the price.
But! That still comes with a pretty steep operational tradeoff. Simply chasing endpoints and optimizing for cost runs the risk of having to juggle way too many vendors and create operational headaches even if it’s shaving off a substantial portion of usage—especially if teams are just running wild with corporate cards. This is especially true for companies that are shipping data to these API providers that are a little less proven (and less-funded) than OpenAI.
The majority of AI in production is still batch processing, which focuses on the use of smaller models. While there’s a class of companies that rely on results that are at a GPT-4 Turbo level of quality (particularly for copilot products), most companies aren’t there and probably won’t be there for a while. Those smaller models are usually good enough (particularly if there’s some light customization on proprietary data).
OpenAI now has to contend with whether Llama 3 creates both an operational and a behavioral shift. Something that’s in shooting distance of GPT-4 is now widely available, and it’s at a comically low price from a lot of providers that have already established themselves as reliable compared to GPT-4 Turbo. Setting aside scores and all that, this is a really tantalizing proposition for companies that have held out on deploying GPT-4 level products due to concerns around cost, latency, security, and reliability. And we haven’t even gotten to customization of Llama 3.

In addition to significantly cheaper and almost good enough endpoints available, most companies at this point understand that hosted versions of all of these—such as those through Together AI—push that cost down even further. The barrier to getting dedicated infrastructure is also dropping, which is also manifesting in a proliferation of pre-training.
It’ll take a while before we start to see how Llama 3’s largest model performs in the wild relative to the degree that Meta has handcuffed it. But these benchmarks are the only things that currently present a buyer an apples-to-apples comparison, and they are really favorable to Meta. (The reality is these comparisons are obviously much more complicated, which we’ll get to in a second.)
OpenAI still offers what’s probably the easiest to use fine-tuning API out there with GPT-3.5 Turbo, which when you talk to developers is one of its more underrated products. But all these endpoint companies are incentivized to push customers to dedicated instances, and they’re going to finesse that pathway to customizing models like Llama 3 to the best that they can.
Inevitably this all benefits Meta. They get new tools to build into their own products and doesn’t have to pay another provider. Their intricate institutional knowledge allows them to squeeze even more power out of something like Llama 3 in the same way it can do with PyTorch. And they build up an insane amount of goodwill amongst developers—which inevitably comes at the expense of more closed developers.
Companies now have a really clear and cheap pathway to more advanced use cases for language models. What that looks like is still unclear (absent of an explosion in new copilots), but Meta may once again be forcing everyone’s hands in a more unexpected way.
Weights & Biases makes a bet on software developers
Before the launch of ChatGPT, one of the hottest areas in machine learning investing was a category we (arguably haphazardly) referred to as machine learning ops—or MLops.
That category comprised a lot of different startups and emerging technologies, such as feature stores with Tecton or frameworks like Anyscale’s Ray. But perhaps the biggest darling among investors and developers of the MLops category is Weights & Biases, which manages one of the most critical workflow components of machine learning: experiment tracking.
But Weights & Biases has also turned into a test case for the single biggest questions for startups in MLOps stack: can these startups building tools for machine learning create an “act two” for a new generation of technologies powered by language models?
Weights & Biases is trying to answer that with the launch of Weave, an updated suite of tooling for evaluating and debugging language models in production. And perhaps more importantly, Weave is targeted at the software engineers that are tasked with putting language models into production in some matter—a departure from its traditional focus on machine learning engineers and classic machine learning.
“We don’t think about machine learning engineers as a subset of software developers, we think about them as something different, and that’s really helped us,” Weights & Biases CEO Lukas Biewald told me. “Now there’s a kind of software developer that’s developing generative AI, and they’re actually having to learn this experimental workflow that’s brand new to them." It’s actually not obvious to some software developers that they should even do that.”
Weave represents a lot of things, but if we wanted to oversimplify it here, it’s effectively a framework to debug LLM apps and (more importantly) try to formalize vibes-based evaluations. While developers fight to one-up each other leaderboards with benchmarking scores or Elo ratings, the reality is the “success” of an LLM internally at companies is often determined from eyeballing the results. They look at loosely-defined evaluation scores (sometimes even based off regex), or customer feedback, or even the results themselves, and are like, yeah, looks good to me.
Language models have inspired a whole new cohort of developers, and many of them are hacker-types that just want to string together a bunch of APIs and tools into something fun. Most language models in production today aren’t necessarily concerned with complicated processes like model lifecycle management. Instead, you can just drop an API into some frontend skin and, voila, you have an AI-powered app.
Most in the field I talk to agree that Weights & Biases pretty much owns the experiment tracking market, even with projects like MLFlow and alternatives like CometML. Early last year, Weights & Biases was in conversations for a funding round that would value the startup at $2 billion and had between $20 million and $23 million in annual recurring revenue. (The round, which was opportunistic, didn’t materialize—though W&B would raise another strategic round later in the year.)
And Weights & Biases continues to quietly grow in the category it effectively helped create, even if it isn’t getting the kind of hype that generative AI application and infrastructure startups are getting. But there are many, many, many more developers than there are machine learning engineers—and they’re often the ones in the room when a CEO walks in and says “put AI in production” with absolutely no additional guidance or context.
Weights & Biases is also quickly becoming a test case of whether a highly-successful MLops company (alongside others in the modern data stack) can grow into a market built around a once-in-a-generation technology. And it’s now moving aggressively to show that it has a large place workflows built on modern AI tooling.
Powering developer workflows in AI
Weights & Biases held its first user conference in June last year and it captured the vibe of AI almost perfectly at that time—incredibly dense, chaotic, a little disorganized (with panels and talks going well into the evening), and overflowing with excitement and energy from attendees despite its practically remote location in the Dogpatch in San Francisco.
At the time, there were glimpses of what Weights & Biases planned for generative AI with the launch of tools for aiding prompt engineering. Its tools were perhaps one of the most well-suited to adapt into generative AI use cases as prompt hacking emerged as an important part of building out workflows on top of language models. (One developer with often describes this to me as “begging the model to do something.”)
This year’s conference was at the Mariott Marquis in San Francisco’s downtown, practically next door to another conference in the venue. Both more subdued and considerably more formal, it also represented the kind of vibe shift in AI from a limitless technology to something that enterprises were over experimenting with, and were looking to actually use it to drive value for their organizations.
As machine learning and deep learning took hold in larger companies, Weights & Biases quickly became a go-to platform for managing the lifecycle of machine learning models. That’s defined by experimentation, testing, iteration, and then (rarely) deployment—and starting the cycle over again. And one of its earliest customers was a small startup at the time that would go on to become arguably the most important company in modern AI: OpenAI.
Weights & Biases still carries a lot of weight when it comes to language models too, if only because of its ongoing deep connections with OpenAI. Earlier this month, OpenAI unveiled a slew of updates to its GPT-3.5 Turbo fine-tuning API. One of the biggest updates was third-party platform integration which, no surprise, included Weights & Biases as its first integration. Fine-tuning, while it offers a lot of potential benefits, is still considered pretty advanced fro most companies—and would by then have likely roped in the MLE team.